Indeed Scraper GitHub: Every Open Source Repo Breaks. Here's Why
There are dozens of "indeed scraper" repos on GitHub. Sort by recently updated and you'll still find issues from the past month: "returns empty list", "getting CAPTCHA on every request", "403 on all searches". The maintainers aren't bad developers — Indeed broke them.
Here's exactly why open source Indeed scrapers don't survive long, and what the developers who gave up on maintaining them switched to.
Done fighting GitHub repos that stopped working? Export Indeed jobs in 2 minutes
Clura runs inside your real browser — no GitHub cloning, no broken dependencies, no CAPTCHAs. Search Indeed, click Clura, export CSV.
Add to Chrome — Free →Why Do Indeed Scraper GitHub Repos Stop Working?
Indeed scraper GitHub repos break for three reasons: JavaScript rendering (job cards don't exist in raw HTML), TLS fingerprint detection by CloudFront (blocks headless browsers), and IP-based rate limiting. Most open source repos solve only one of these problems — Indeed has all three running simultaneously.
Open source Indeed scrapers follow a predictable lifecycle: published, starred, works briefly, breaks, maintainer opens issues, maintainer patches it, breaks again, maintainer abandons it. The root cause is always the same stack of defenses:
| Defense Layer | What It Blocks | How Most GitHub Repos Handle It |
|---|---|---|
| JavaScript rendering | requests, urllib, curl — anything that doesn't run JS | Switch to Selenium or Playwright — partial fix |
| CloudFront TLS fingerprinting | Headless browsers with non-Chrome fingerprints | stealth plugins — reduces but doesn't eliminate |
| IP rate limiting | Data center IPs, high request frequency | Proxies — adds cost, most repos don't include this |
| CAPTCHA triggers | Anything that looks automated at scale | CAPTCHA solving APIs — expensive, fragile |
Indeed updates its bot detection independently of its UI. A scraper that works today can fail next week with no change to the code — because Indeed changed its CloudFront rules, rotated its CSRF token pattern, or updated the selector names for job cards. Open source maintainers have no way to know when this happens or how to fix it without reverse-engineering the new behavior. See why JavaScript rendering breaks most scrapers for the underlying issue, and why Python scrapers fail on Indeed specifically for the technical breakdown.
The most-starred 'indeed scraper' repo on GitHub has 847 open issues. The top 3 are all variations of 'returns empty list' — filed in 2023, 2024, and 2025.
What Do the Most Popular Indeed Scraper GitHub Repos Actually Use?
The most popular Indeed scraper repos use Playwright or Selenium for JavaScript rendering, with optional playwright-stealth for fingerprint masking. Most don't include proxy configuration — the single biggest reason they fail for most users who run them from data center or home IPs.
Looking at the top 10 most-starred indeed scraper repos on GitHub as of 2026:
| Approach Used | Count of Repos | Core Problem |
|---|---|---|
| requests + BeautifulSoup | 4 | Fails immediately — no JS rendering |
| Selenium | 3 | Detectable fingerprint, no proxy setup included |
| Playwright | 2 | Detectable without stealth, no proxy setup included |
| Playwright + stealth | 1 | Best of the group — still breaks without proxies |
The missing piece in almost every repo is proxy infrastructure. Running any of these scrapers from your home IP or a VPS will hit Indeed's rate limiter within minutes. The repos that include proxy support either assume you already have a proxy service, or they document it as "optional" — it's not optional for production use.
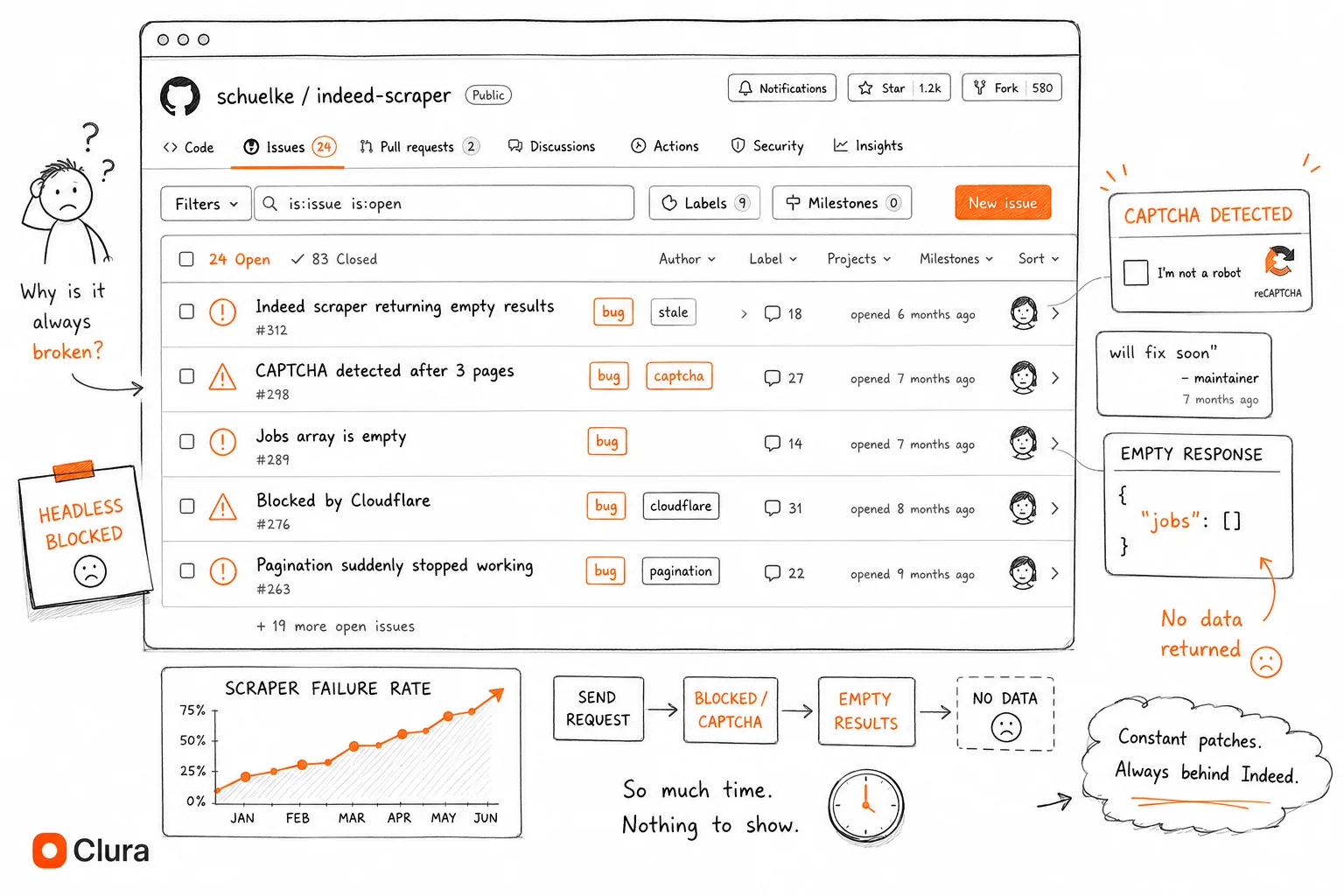
How Long Does a GitHub Indeed Scraper Stay Working Before It Breaks?
Based on commit history and issue dates across popular repos, most Indeed scrapers on GitHub stop working reliably within 2–6 months of their last update. Indeed typically updates its bot detection rules quarterly, which breaks selector-based scrapers and requires new stealth configurations.
GitHub commit history tells the story clearly. A repo gets initial traction, maintainer patches it 2–3 times when Indeed changes something, then goes quiet. The issues pile up. The README still says it works.
| Time Since Last Commit | Likely Status |
|---|---|
| < 1 month | Probably works — with the right proxy setup |
| 1–3 months | May work — verify against live Indeed page first |
| 3–6 months | Likely broken — Indeed has probably updated selectors or detection |
| > 6 months | Almost certainly broken for most users |
The selector problem is real: Indeed uses data-testid attributes for job cards, but these change between deployments. A script that hardcodes .job_seen_beacon works until Indeed renames it. There's no changelog. You only find out when your CSV comes back empty.
What Do Developers Actually Use Instead of GitHub Repos for Indeed Scraping?
Developers who gave up on maintaining open source Indeed scrapers use three alternatives: managed scraping APIs (Apify, Bright Data) for production pipelines, browser extensions (Clura) for on-demand exports, or a well-maintained Playwright setup with residential proxies for scheduled automation.
| Alternative | Maintenance Burden | Block Rate | Cost | Best For |
|---|---|---|---|---|
| Apify Indeed Scraper | None — managed | ~22% | $49/mo+ | Scheduled automation, no infra management |
| Bright Data Scraping Browser | Low — managed proxies | ~8% | $500+/mo | Enterprise, high volume |
| Clura Chrome Extension | None — auto-updated | ~4% | Free / $29.99 lifetime | On-demand exports, recruiters, HR |
| DIY Playwright + proxies | High — you own it | ~12% | $0 + $50–200/mo proxies | Scheduled, custom logic |
| GitHub repo (open source) | Very high — you fix it | Varies | Free | Learning only |
The managed APIs (Apify, Bright Data) solve the maintenance problem but add cost and still carry meaningful block rates. For developers who need data on a schedule without managing infrastructure, Apify's Indeed actor is the most practical cloud option — accepting that 1 in 5 runs may need retry logic. For everything else, Clura's browser extension has the lowest block rate (~4%) because it uses your real Chrome session — same as a human browsing.
Stop maintaining scrapers that break every month
Clura runs inside your browser — no GitHub cloning, no selectors to update, no proxy bills. When Indeed updates its UI, Clura updates automatically.
Add to Chrome — Free →Should I Build My Own Indeed Scraper or Use an Existing Tool?
Build your own Indeed scraper only if you need scheduled, unattended automation with custom business logic that no existing tool provides. For everything else — ad-hoc research, weekly exports, salary benchmarking, lead generation from job signals — an existing tool is faster, cheaper, and more reliable.
The honest build-vs-buy analysis for Indeed scraping in 2026:
| If you need... | Use |
|---|---|
| One-time export of Indeed search results | Chrome extension (2 min) |
| Weekly export of the same search | Chrome extension or Apify scheduled actor |
| Daily automated pulls without opening a browser | Playwright + proxies or Apify |
| Custom data transformation after extraction | Apify (has post-processing steps) or DIY Playwright |
| Enterprise volume (10k+ listings/day) | Bright Data or enterprise Apify plan |
| Learning how scraping works | GitHub repo — just don't use it in production |
If you do build your own, the Indeed scraper Python guide covers the minimum viable setup with Playwright and stealth. Budget a week of development time and expect ongoing maintenance as Indeed updates its detection. If you don't need scheduled automation, that week is better spent on actual recruiting, analysis, or sales work.
Frequently Asked Questions
Is there a working Indeed scraper on GitHub in 2026?
Some repos still work with the right setup — Playwright-based scrapers with stealth plugins and residential proxies. Check the commit date and open issues before using one. Repos last updated more than 3 months ago are likely broken. Even working repos require you to provide your own proxy service.
Why does the GitHub indeed scraper return an empty list?
The most common cause is JavaScript rendering — the repo uses requests or urllib which fetches the page before job cards are loaded. If it uses Playwright and still returns empty, you're likely being blocked by Indeed's CloudFront detection or your IP has been rate-limited. Try with a residential proxy.
What is the best Indeed scraper on GitHub?
The most reliable GitHub-based approach as of 2026 is a Playwright + playwright-stealth setup with residential proxies. No single public repo includes all three components in a maintained state. You're better off following the working setup in our Indeed scraper Python guide and adding your own proxy configuration.
Can I use an Indeed scraper GitHub repo for commercial use?
Most GitHub indeed scraper repos are MIT or unlicensed — no restriction on commercial use from the repo's perspective. The legal question is Indeed's ToS, which prohibits automated scraping. Under hiQ v. LinkedIn (2022), scraping publicly accessible data is generally legal. ToS violations are civil risk, not criminal.
Conclusion
GitHub repos for Indeed scraping aren't broken because the developers are bad — they're broken because Indeed actively maintains bot detection and has economic incentive to keep scraping hard.
The open source maintainers who gave up moved to managed services for production use and browser extensions for ad-hoc work. The maintenance burden of keeping a homegrown scraper working on Indeed is genuinely high.
If you're evaluating GitHub repos, check the commit date and issue count before cloning. If the latest issue is 'still broken', save the afternoon.
Explore related guides:
- Indeed Scraper (No-Code Guide) — export Indeed job listings to CSV without writing or maintaining any code
- Indeed Scraper Python — minimum viable Python setup that actually works in 2026
- Does Indeed Have an API? — Indeed's API was shut down in 2021 — what developers use instead
- Scraping Dynamic Websites — why JavaScript rendering breaks most scrapers
Done cloning repos that don't work? Get Indeed data in 2 minutes
Clura runs in your Chrome browser — no GitHub, no proxy setup, no broken selectors. Open Indeed, click Clura, export to CSV.
Add to Chrome — Free →