HTML Table to Excel: Extract Website Tables in 2026
If pandas.read_html() is returning an empty list — or your HTML table extractor is coming back with blank rows — the problem is almost always JavaScript rendering. The data visible in your browser wasn't in the page's raw HTML. Any tool that reads source HTML before JavaScript runs will miss it.
This guide covers two reliable methods to convert an HTML table to Excel or CSV: a no-code table extractor Chrome extension that reads the fully rendered page, and pandas.read_html() for static HTML tables. You'll know exactly when each works — and what to do when standard tools fail. For broader tool choices, see the best web scrapers comparison and the free web scraping tools guide.
Extract Any Website Table to Excel
Clura detects table rows automatically and exports a clean spreadsheet in minutes. Start free, then unlock unlimited scrapes and records with the $29.99 lifetime plan.
Add to Chrome — Free →What Are Website Tables
A website table is a structured HTML element that displays information in rows and columns — each row represents a record and each column represents a field. Tables are one of the most straightforward formats to extract structured data from automatically because the data is already organized.
For example, a product comparison table already maps directly to rows in a spreadsheet:
| Product | Price | Rating | Stock |
|---|---|---|---|
| Laptop A | $899 | 4.5 | In Stock |
| Laptop B | $799 | 4.3 | In Stock |
| Laptop C | $1,099 | 4.7 | Low Stock |
An AI scraper detects this structure automatically and exports every row as a record in your spreadsheet — whether the table has 10 rows or 10,000.
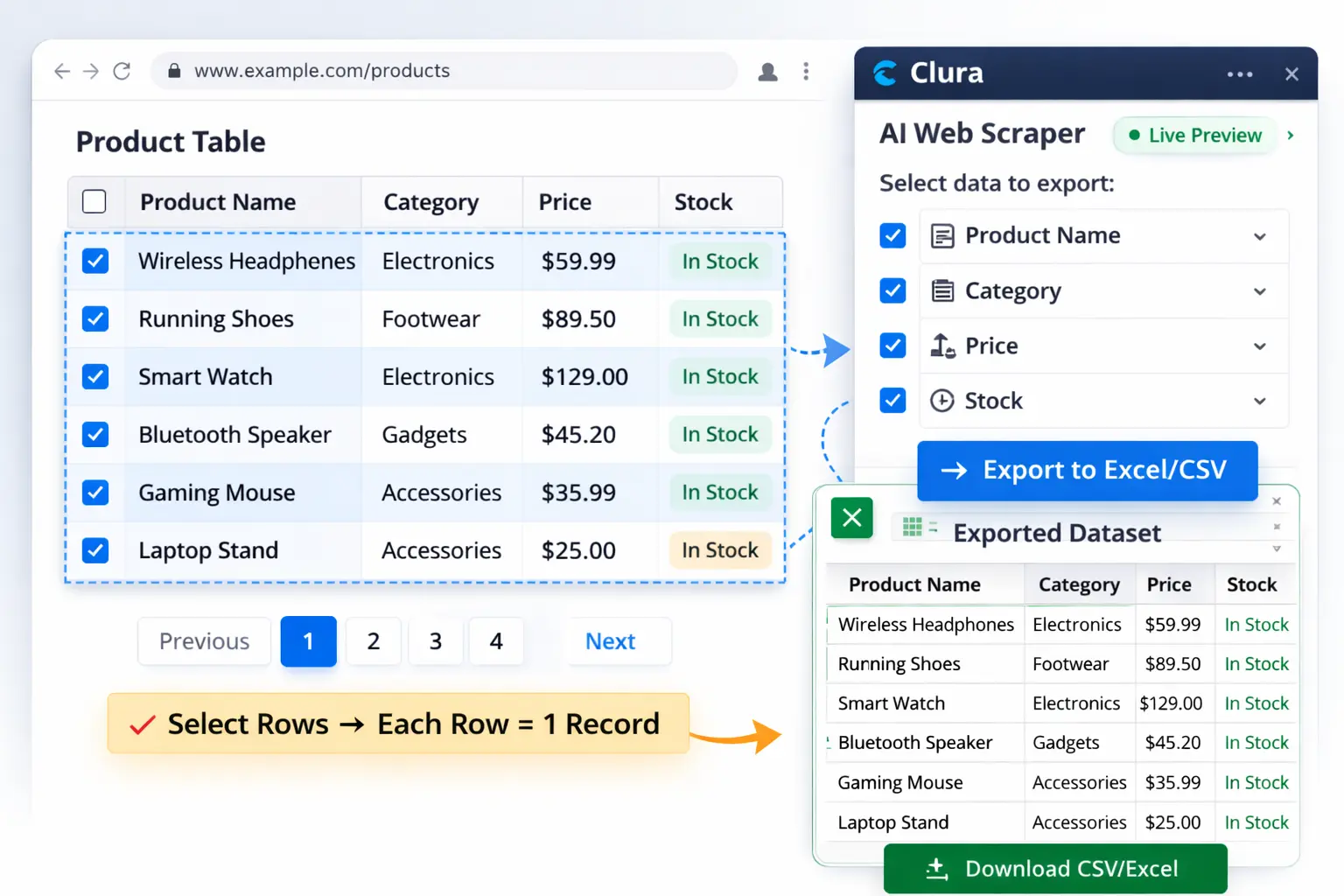
Why Businesses Extract Data From Website Tables
Businesses extract data from website tables to build structured datasets for market research, lead generation, price monitoring, and financial analysis — any workflow that depends on regularly updated data from competitor or reference sites.
Market Research and Price Monitoring
Competitor websites often publish pricing, product features, and availability in comparison tables. Extracting these tables allows businesses to track changes over time and adjust their own pricing strategy without visiting each page manually.
Lead Generation
Business directories frequently list companies in table format with fields like company name, website, location, and contact details. Sales teams extract these tables to build prospect databases and import them directly into CRM systems for outreach.
Financial Data Collection
Financial websites publish stock prices, company statistics, and economic indicators in tabular format. Analysts extract this data for research, modeling, and portfolio tracking — work that would take hours if done manually.
Research and Academic Datasets
Research reports, government databases, and public portals present datasets in HTML tables. Extracting these tables saves hours of manual copying and eliminates the transcription errors that come with it.
How Table Data Is Structured on Websites
Website tables use HTML table elements — <table>, <tr>, and <td> — to organize data into rows and columns. Each <tr> is a record and each <td> is a field value. This consistent structure is what makes tables straightforward to extract automatically.
Here is how manual copying compares to automated extraction:
| Method | Speed | Accuracy | Scales to 1,000+ rows |
|---|---|---|---|
| Manual copy-paste | Very slow | Error-prone | No |
| AI web scraper | Seconds | Consistent | Yes |
Some websites simulate tables using div-based layouts rather than proper HTML table tags. AI scrapers handle these cases by detecting the repeating visual pattern on the rendered page — so the extraction works regardless of how the developer built the markup.
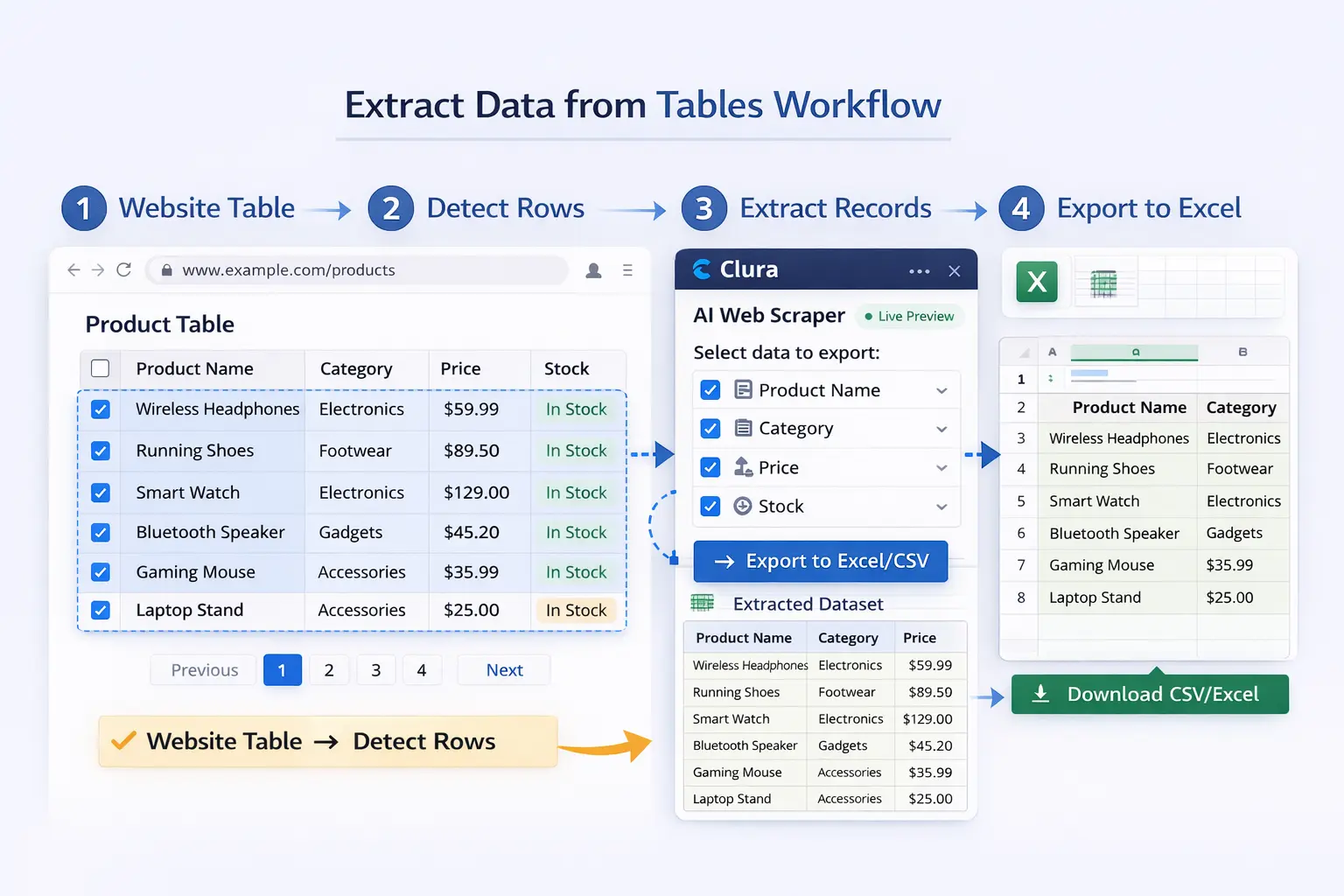
How to Extract Data From Website Tables (Step-by-Step)
To extract data from a website table: open the page in Chrome, use an AI scraper to detect the table structure, preview the extracted records, and export to CSV or Excel in one click — no selectors or code required at any step.
Step 1 — Open the Target Page
Navigate to the webpage containing the table you want to extract. Common examples include product comparison pages, business directories, job listing sites, and financial data portals. The table should be fully visible in the browser before you begin.
Step 2 — Describe What You Want
Using an AI scraper like Clura, describe the data you want to collect in plain language. For example: "Extract company name, location, website, and phone number from every row in this table." No CSS selectors or HTML knowledge required.
Step 3 — Extract All Rows Automatically
The AI detects the table structure and collects every row automatically — whether the table has 20 rows or 2,000. If the table spans multiple pages, the scraper navigates pagination and continues collecting until the full dataset is assembled.
Step 4 — Preview the Dataset
Before exporting, review the extracted data in a table preview. Confirm the right columns were captured. If something looks off, adjust your description and re-run — the whole process takes seconds.
Step 5 — Export to CSV or Excel
Once the dataset looks correct, export it as CSV or Excel with a single click. The file is immediately ready to open and analyze — no additional formatting or cleanup required.
Extract Tables From Any Website
Clura's AI web scraper Chrome extension detects table rows automatically and exports a clean spreadsheet — directly from your browser.
Add to Chrome — Free →How to Convert HTML Table to Excel: No-Code and Python
There are two reliable ways to convert an HTML table to Excel. A no-code browser extension works for any user on any site. pandas.read_html() works for Python developers on static pages. Here's when to use each — and when both fail.
Method 1: No-Code HTML Table Extractor (Clura)
The fastest approach is a Chrome extension that acts as an HTML table extractor inside your live browser session. Clura detects HTML <table> elements and div-based table layouts on the rendered page, lets you select the right table, and exports a clean .xlsx file in one click. Because it runs after JavaScript has executed, it captures table data that loads dynamically — the rows that pandas.read_html() and server-side scrapers miss entirely.
Setup: 2 minutes. Navigate to the page, open Clura, select the table, export. No selectors, no API keys, no Python environment.
Method 2: pandas.read_html() for Python
pandas.read_html() extracts all HTML tables from a URL directly into a list of DataFrames. For static pages it's a one-liner:
import pandas as pd
tables = pd.read_html("https://example.com/data-table")
df = tables[0] # first table on the page
df.to_excel("output.xlsx", index=False) # HTML table to Excel
df.to_csv("output.csv", index=False) # HTML table to CSV
When it fails: pd.read_html() reads the raw HTML response — before JavaScript runs. On any modern site where the table loads via JavaScript, it returns an empty list or raises ValueError: No tables found. For those cases, you need Playwright to render the page first, then pass the HTML to pandas — or use Clura directly. For a full breakdown of why JavaScript breaks standard scrapers, see how to scrape dynamic websites.
Which Method to Use
| Situation | Best Method |
|---|---|
| Static HTML table (Wikipedia, government data) | pandas.read_html() or Clura |
| JavaScript-rendered table (Amazon, LinkedIn, job boards) | Clura (browser session reads rendered page) |
| Scheduled automation, unattended runs | Playwright + pandas |
| One-off export, no coding | Clura |
HTML Table Extractor Tools Compared
| Tool | JavaScript tables | No-code | Export format | Best for |
|---|---|---|---|---|
| Clura (table extractor Chrome extension) | ✅ Yes | ✅ Yes | CSV, Excel | Any table, static or dynamic |
| Instant Data Scraper | ❌ No | ✅ Yes | CSV, Excel | Static HTML tables only |
| pandas.read_html() | ❌ No | ❌ Python required | CSV, Excel, any | Developers, static pages |
| Playwright + pandas | ✅ Yes | ❌ Code required | CSV, Excel, any | Scheduled automation |
For a deeper comparison of browser-based table scraper extensions, see the web scraper Chrome extension guide.
Challenges When Extracting Data From Website Tables
The main challenges when extracting data from website tables are tables built with div elements instead of HTML tags, content loaded dynamically by JavaScript, and data split across paginated pages — all of which browser-based AI scrapers handle automatically.
Div-Based Table Layouts
Many modern websites display tabular information using div elements instead of proper HTML table tags. Simple scrapers that only look for <table> elements will fail on these pages. AI-based scrapers detect the repeating visual pattern on the rendered page regardless of the underlying markup.
Dynamically Loaded Tables
Some websites load table content using JavaScript after the initial page render. Traditional server-side scrapers read raw HTML and cannot see this content. Browser-based scrapers run inside Chrome and see the fully rendered page — including all JavaScript-loaded table data.
Paginated Tables
Large datasets are often split across multiple pages with "Next" buttons or numbered pagination. A scraper must detect and navigate each page to build a complete dataset. A tool that only collects the first page will miss the majority of the available records.
Real Use Cases for Website Table Data Extraction
The most common use cases for website table extraction are ecommerce price monitoring, job market research, lead generation from business directories, and financial data collection — any dataset that is already structured and publicly visible on a webpage.
Ecommerce Price Monitoring
Online retailers extract product comparison tables from competitor sites to track pricing, availability, and feature differences. The data is exported to Excel and reviewed regularly to inform pricing decisions and identify market opportunities.
Job Market Research
Recruiters and HR analysts extract job listing tables from job boards and careers pages to track demand, benchmark salaries, and monitor competitor hiring activity. A structured spreadsheet of job titles, companies, locations, and salary ranges is far more actionable than browsing job sites manually.
Lead Generation From Business Directories
Business directories present company data in paginated tables with fields like company name, address, phone number, and website. Sales teams extract these tables using Clura's AI web scraper and import the results into CRM systems for targeted outreach campaigns.
Financial and Research Data
Researchers and analysts extract structured data from financial portals, public databases, and academic sources. Automated table extraction replaces hours of manual copying with a process that takes seconds and produces a clean, error-free dataset.
Frequently Asked Questions
Can I extract tables from any website?
Most publicly visible tables can be extracted automatically. Some websites use div-based layouts that mimic tables, or load table content dynamically with JavaScript — browser-based AI scrapers handle both cases because they run on the fully rendered page.
Can I export website tables to Excel?
Yes. Once a table is extracted, the data can be exported directly to Excel (.xlsx), CSV, or Google Sheets with a single click. The exported file is structured and ready for analysis without additional formatting.
Is scraping tables from websites legal?
Scraping publicly available data is generally legal in most jurisdictions. Always review the terms of service of any website before extracting data and comply with regulations such as GDPR when handling personal data.
Can I extract tables from dynamic websites?
Yes. Modern browser-based AI scrapers run inside Chrome and see the fully rendered page — including table data loaded dynamically by JavaScript. This makes them well-suited for financial sites, job boards, and any site that loads table content after the initial page load.
What is the difference between a table scraper and a general web scraper?
A general web scraper collects any repeating data structure on a page — cards, lists, or tables. A table scraper specifically targets HTML table elements. AI-based scrapers like Clura handle both automatically, detecting whether data appears in a table or a card layout without any configuration.
How do I convert an HTML table to Excel automatically?
Two reliable methods: use a Chrome extension like Clura to export the table directly from your browser as .xlsx in one click, or use pandas.read_html(url) in Python to pull the table into a DataFrame and call df.to_excel("output.xlsx"). The Chrome extension works on both static and JavaScript-rendered tables. pandas.read_html() works only on static HTML — it fails on JavaScript-rendered tables with a ValueError: No tables found error.
How do I convert an HTML table to CSV?
Two ways: with pandas, call df.to_csv("output.csv", index=False) after pd.read_html(). With a no-code table extractor Chrome extension like Clura, open the page, click the extension, and select CSV export in one click — no Python environment needed. The Chrome extension also handles JavaScript-rendered tables that pd.read_html() cannot parse, returning a ValueError: No tables found.
What is pandas read_html and when does it fail?
pandas.read_html() is a Python function that fetches a URL and parses all HTML <table> elements into a list of DataFrames. It's fast and clean for static pages — Wikipedia tables, government datasets, financial pages with direct table URLs. It fails when the table data loads via JavaScript after the initial HTML response, which is the case on most modern websites. The error is typically ValueError: No tables found or an empty list. The fix is either Playwright to render the page first, or a browser-based extractor like Clura that reads the already-rendered session.
Why is my HTML table extractor returning empty rows?
Almost always JavaScript rendering. Most HTML table extractors — including pandas.read_html() and BeautifulSoup — read the page's raw HTML before JavaScript executes. If the table rows are injected by JavaScript after load, the extractor sees empty <tbody> elements instead of real data. The fix: use a browser-based tool that runs inside a live Chrome session where the page is already fully rendered. See how to scrape dynamic websites for the full explanation.
Conclusion
Website tables already contain structured data — rows, columns, and labeled fields. Extracting that data should be fast and straightforward, not hours of manual copying.
With a browser-based AI scraper, you can extract an entire table, navigate its pagination automatically, and export a clean spreadsheet in minutes. The result is a structured dataset ready for analysis, reporting, or import into any tool in your stack.
Explore related guides to go further with your data collection workflow:
- AI Web Scraper Chrome Extension — how Clura's AI scraper works
- Scrape Website Data — complete guide to extracting any website data to Excel or CSV
- Scrape Dynamic Websites — why JavaScript-rendered tables break most extractors and how to fix it
- Web Scraper Chrome Extension Guide — comparing browser-based HTML table scrapers
Convert Any HTML Table to Excel — Free
Clura detects HTML table rows automatically and exports a clean .xlsx file in one click. Works on static and JavaScript-rendered tables alike. Start free, then use the $29.99 lifetime plan for unlimited scrapes and records.
Add to Chrome — Free →